Data | Data Science and AI | Software Development
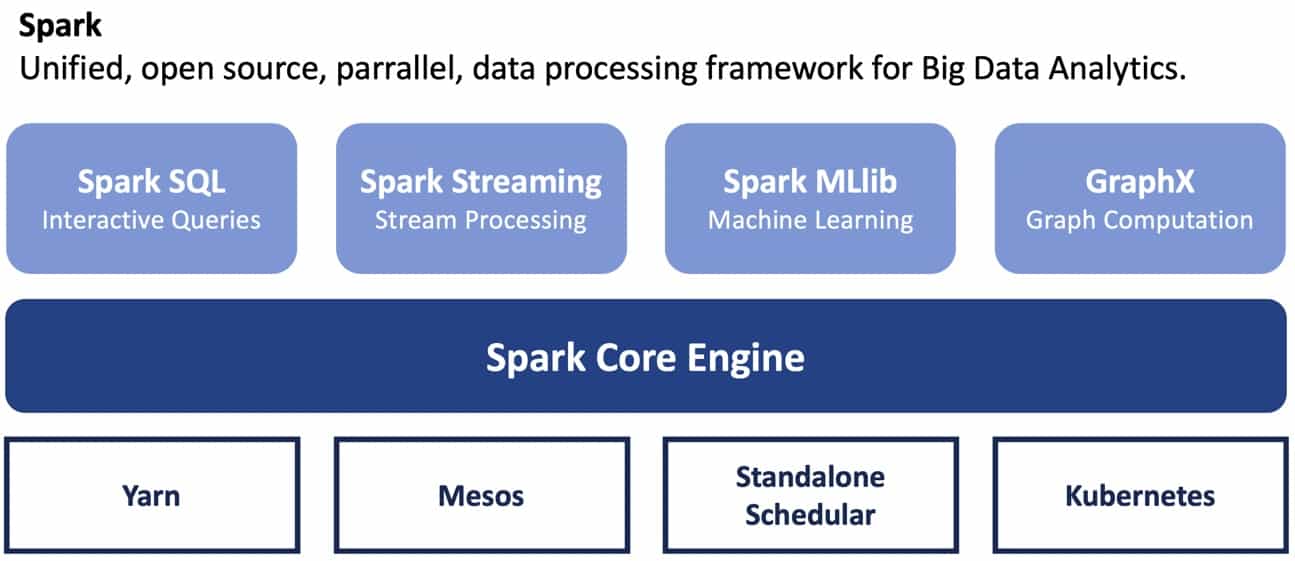
Apache Spark 
Jan Toebes 03 Feb, 2015





Data processing with Spark is a part of almost any data platform. There are several ways how to run and use Spark. You may run Spark in local, client or cluster mode, choose different resource managers or go for a managed service from one of the popular cloud providers. In this blog post we’ll share our findings from building a data platform with Spark using Kubernetes as the resource manager.
In this blog we suggest an architecture of a data platform where Spark runs on Kubernetes, components are built with Helm 3, and Argo is chosen as a workflow scheduler.
Besides being modern and highly developing open source technology, there are many other reasons to go for Kubernetes. Kubernetes allows you to deploy cloud native applications anywhere and manage them the way you like. Using containers under the hood it makes your application consistent regardless of the environment you deploy it to. Kubernetes manages the life-cycle of applications and, with the help of package managers (f.e. Helm), can do versioning and dependency management. But why would you use Kubernetes as the resource manager for Spark when Yarn is still the most widely used one?
When should you consider using Kubernetes with Spark:
Nothing comes for free and running Spark with Kubernetes as resource manager has a list of extra complexities you need to consider.
The most important complexity is maintaining Kubernetes cluster itself. Of course, it gets easier if you use managed services from cloud providers, still a lot of support and administration is your responsibility. Another complexity comes from the early support of Kubernetes with Spark (first introduced in Spark 2.4). With the release of Spark 3.0 the Kubernetes implementation becomes more mature and robust, but most of the existing architectures are dependent on Spark 2.4 and will stay with it for a while for different reasons (support of ML libraries is one of them).
The most important and often underestimated complexity comes from the user adoption. Depending on your implementation, users are required to have a certain level of knowledge in Docker, Kubernetes, and networking.
There are 3 standard ways of running Spark applications on Kubernetes:
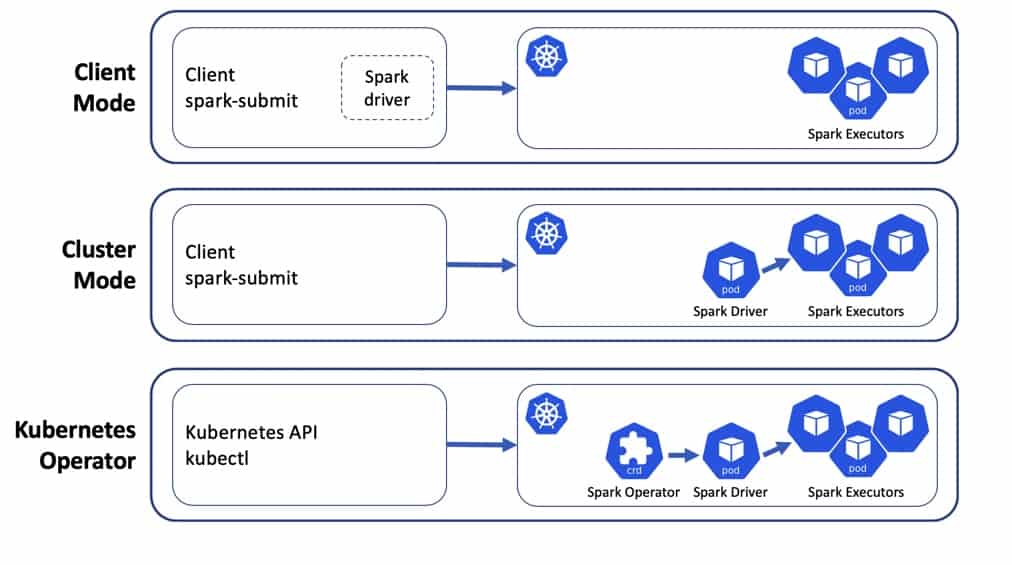
In the client mode when you run spark-submit you can use it directly with Kubernetes cluster. In this case the flow is the following:
spark-submit, starts Spark driver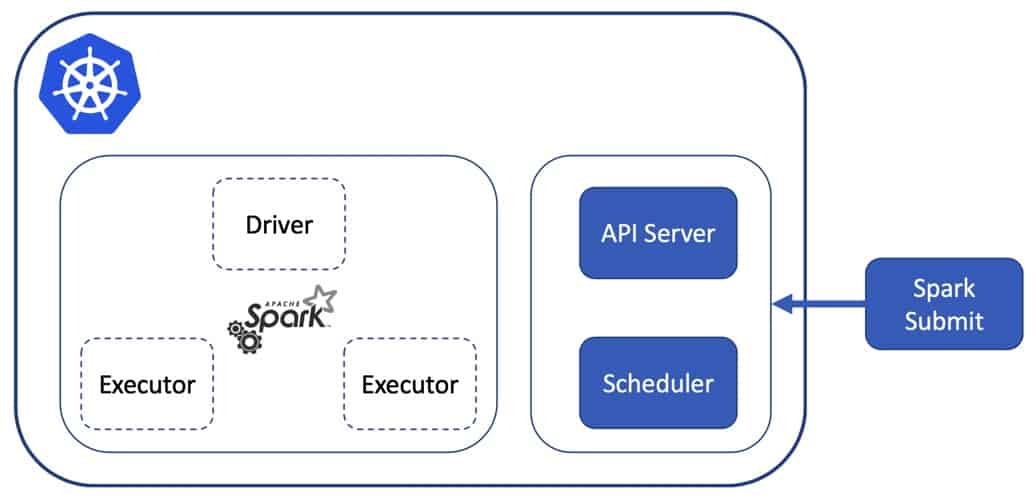
You can also run it differently, by having a pod with Spark constantly running, allowing you to submit applications from it. The rest of the process will be the same, but your driver in this case will be just a process in the pod where Spark is installed.
Case 1– starting the driver process as a container argument.
In this case initiation of a Spark application happens right after kubectl apply -f spark-pod.yaml or kubectl run spark-app --image myspark-image ... command.
apiVersion: apps/v1
kind: Pod
spec:
template:
spec:
containers:
- name: my-spark-application
image: "mycompany/spark-3.0.0:prod"
command: ['/opt/spark/bin/spark-submit my-spark-app.py']Case 2 – Spark Client pod is constantly running and the Driver process is started via ssh call (login to the pod or run remote ssh command). Availability of the pod is guaranteed by the Deployment object.
apiVersion: apps/v1
kind: Deployment
spec:
template:
spec:
containers:
- name: my-spark-application
image: "mycompany/spark-3.0.0:prod"
command: ['/bin/bash']Then a developer/analyst/scientist will login to the pod via kubectl exec -ti $SPARK_POD bash, and run the command /opt/spark/bin/spark-submit my-spark-app.py inside the pod. The benefit of this approach is the ability to operate like on your own machine.
It’s important to mention that Spark Kubernetes Operator is not officially released yet. You can check it out here and evaluate if it’s something you want to give a try.
As a developer or data scientist, you often use Spark in interactive mode during the exploration and testing phase of the development process. But your goal is to run Spark applications on a regular basis. In real world examples you hardly solve all your problems with only one Spark application. In most cases you need to process your data in multiple steps, move it to another format and store it in different storage. To perform these actions you need a workflow (WF) orchestrator. There are a lot of options that can be used, but for this implementation we’ll consider three of them: Oozie, Airflow and Argo.
A lot of older systems use Oozie to automate Spark applications. Oozie is a workflow orchestrator that can execute directed acyclic graphs (DAGs) of specific actions (think Spark application, Apache Hive query, and so on) and action sets. It is possible to make Oozie use Spark on Kubernetes, but running Oozie itself on Kubernetes requires extra implementation. You might consider this option if you have a huge volume of Ozzie workflows and lift-and-shift is your chosen approach for migration.
Airflow is another very popular WF management tool. It’s open-source, uses Python to describe WF, has huge support from the community, and has a pretty UI. To run your Spark applications on Kubernetes you will communicate with it using the Kubernetes python client. It will allow you to create and manage applications. Airflow itself can run within the Kubernetes cluster or outside, but in this case you need to provide an address to link the API to the cluster.
Argo workflows is an open source container-only workflow engine. It is implemented as a Kubernetes Operator. Every WF is represented as a DAG where every step is a container. It’s also highly configurable, which makes support of Kubernetes objects like configmaps, secrets, volumes much easier. Unlike Airflow, where the main development language is Python, Argo uses yaml, which is good and bad at the same time. Managing yaml’s can be problematic, especially with the growing number of steps and dependencies for a WF. Argo UI is not mature enough to provide a full WF management lifecycle. Though you get out of the box traceability of Kubernetes, where kubectl describe, kubectl get are available and provide enough information.
There are other WF orchestration tools as well. Although choosing the correct tool is fully dependent on the requirements and available resources, we want to focus on Argo Workflows for the following reasons:
One of the suggested ways is to use WorkflowTemplate objects, they allow to register a parameterizable template and call it from a DAG step definition with certain parameters.
kind: WorkflowTemplate metadata: name: spark-app-workflow-template spec: arguments: parameters: - name: sparkJobFilePath templates: - name: spark-submit inputs: parameters: - name: sparkJobFilePath container: image: mycompany/spark-3.0.0:prod command: [sh, -c, ] args: [ "/opt/spark/bin/spark-submit {{ <code>{{}}inputs.parameters.sparkJobFilePath{{}}}}" ]
Here is a snippet of Argo Workflow definition. It has a DAG with one step which refers to a WorkflowTemplate and passes a single parameter, location of the spark application file.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
templates:
- name: template-1
dag:
tasks:
- name: step-1
templateRef:
name: my-spark-app
template: spark-submit
arguments:
parameters:
- name: sparkJobFilePath
value: /mounted/volume/spark-apps/my-spark-app.py
Current setup is enough to run your WF’s with Spark on Kubernetes. When you’re moving into production ready solution, more questions pop-up:
In most cases, data access depends heavily on your current infrastructure. Data access might be a bottleneck in terms of performance, but also a source of extra complexity (for instance, if you have all data stored in a Kerberized HDFS cluster, you need to implement token propagation to all pods). Also if you use Hive as the metastore, you might need to have Thrift server running somewhere in your Kubernetes environment to provide you with access to Hive.
If you run Spark on Kubernetes in client mode, you need to have access to the code of Spark application locally. In most cases it’s not a problem. Things get more complicated when you want to run Spark applications in cluster mode. In this case you need to copy your code to the pod of your driver. When we talk about one application, it’s not a problem to run kubectl cp command, but it’s highly inefficient when we have to work with a big amount of code and/or when you are testing your application. The topic of GitOps is currently very popular. As soon as we’re using Argo Workflows it makes sense to look for GitOps tools in the same stack: Argo CD.
Argo CD is a declarative, GitOps continuous delivery tool for Kubernetes. Idea behind Argo CD is quite simple: it takes Git repository as the source of truth for application state definition and automates the deployment in the specified target environment. It can also track updates on branches, tags or be pinned to specific commits. It can also take a Helm chart as a unit of deployment.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-helm-chart
namespace: argocd
spec:
project: default
source:
path: my-helm-chart
repoURL: https://github.com/my-helm-chart
targetRevision: HEADArgo Workflows helps you to define and run your WF’s, but what about scheduling WF’s based on some external events or a specific date? Although in other schedulers it comes out of the box (in Oozie it’s part of your WF definition, in Airflow everything is scheduled Cron based, but there is also a concept of sensors, which allows your WF to react on specific events). Argo Workflows has no scheduling mechanism. For that you need to use Argo Events infrastructure.
Argo Events is an event-based dependency manager for Kubernetes which helps you define multiple dependencies from a variety of event sources like webhook, S3, schedules, streams etc. and trigger Kubernetes objects after successful event dependencies resolution.
Typical example could be a calendar event source with a gateway:
Registering Gateway:
apiVersion: argoproj.io/v1alpha1
kind: Gateway
metadata:
name: my-calendar-gateway
spec:
type: calendar
eventSourceRef:
name: calendar-source
processorPort: 9330
template:
metadata:
name: calendar-gateway
spec:
containers:
- name: "gateway-client" // Gateway client manages the event source for the gateway.
image: argoproj/gateway-client:v0.12
command: ["/bin/gateway-client"]
- name: "calendar-events" // Calendar event source
image: argoproj/calendar-gateway:v0.12
command: ["/bin/calendar-gateway"]
subscribers:
http:
- http://my-calendar-sensor.argo-events.svc:9300/This setup will react to further registration of the calendar event and notify subscribers
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: calendar-source
spec:
type: calendar
calendar:
- name: schedule-a
expression: "0 23 * * *"In general, all mentioned components should form the skeleton of your data platform. In production ready examples it may and should be extended with different components to serve the purpose. Some to mention is Spark History Service, which is not a part of Spark application and should be installed as a separate application. Depending on the usage of this platform, you can also consider running Jupyter notebooks and other tools, but this is beyond the scope of this blog post.
To run Spark on Kubernetes you need to implement not a lot of Kubernetes objects. In the nutshell your set-up will consist of deployment, configuration map, pvc, role binding and service objects. But when the size of your system grows by introducing other components, the amount of yaml’s in your projects becomes hard to manage. For this reason, we considered Helm as package manager for K8s.
Helm helps you manage Kubernetes applications by using Helm Charts to help you define, install, and upgrade complex Kubernetes applications. Charts are easy to create, version, share, and publish. One important feature of Helm is the possibility to use dependent charts within your chart, which drastically reduces the amount of copy-paste and makes your project easier to maintain.
The high level view on the architecture is present here. Note that we show only the most important components. This architecture may be extended with more components as needed for the production-ready system. All tools we consider in our implementation are open source and have great community support.
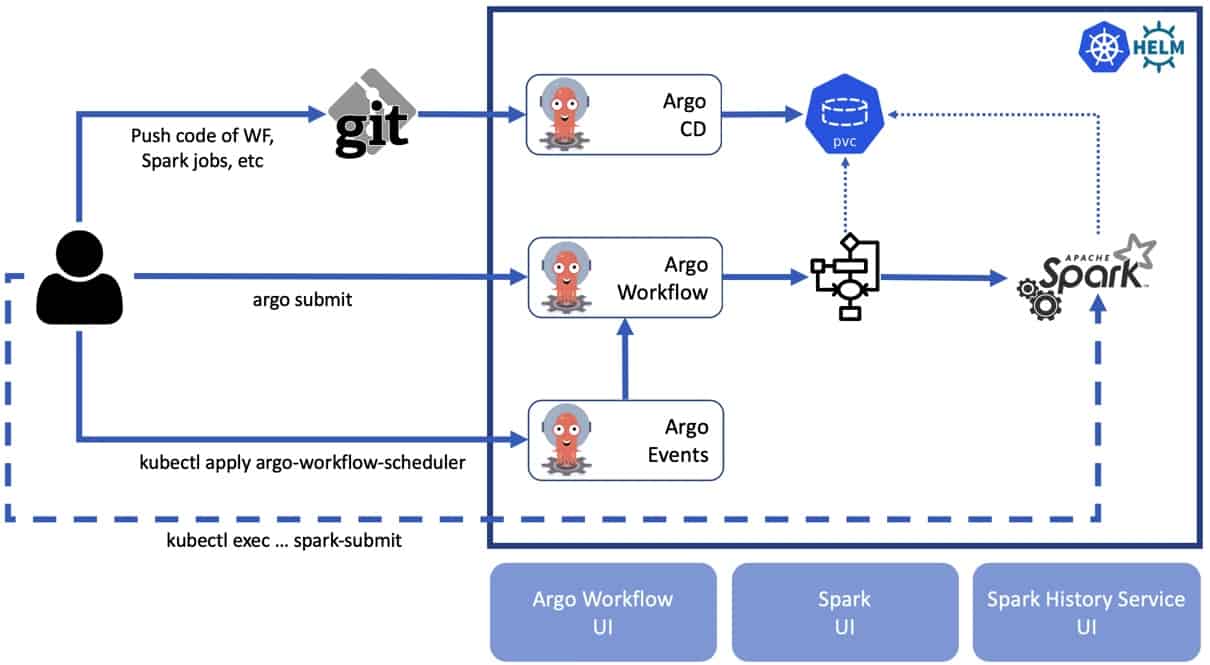
The final architecture consists of the following components:
PySpark and spark-history-service tailored images are the foundation of the Spark ecosystem.
Argo WorkflowTemplate and DAG based components.
This chart can bring the foundation of the infrastructure and most of the charts will inherit from it. Collects reusable components like:
Declaring volume as a configmap:
{{- define "common.spark-defaults-conf-volume" -}}
- name: spark-defaults-conf
configMap:
name: {{ include "spark-client.cm-name-spark-defaults" . }}
{{- end -}}Declaring general way to mount the volume:
{{- define "common.spark-defaults-conf-volumeMount" -}}
- name: spark-defaults-conf
mountPath: /opt/spark/conf/spark-defaults.conf
subPath: spark-defaults.conf
{{- end -}}Defining a generic list of labels for a Spark application:
{{- define "common.labels" -}}
app: {{ include "common.name" . }}
{{- range $key, $val := .Values.appLabels.custom }}
{{ $key }}: {{ $val }}
{{- end }}
spark.instance: {{ include "common.name" . }}
helm.sh/chart: {{ include "common.chart" . }}
app.kubernetes.io/name: {{ include "common.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
app.kubernetes.io/version: {{ .Chart.Version | quote }}
app.kubernetes.io/managed-by: {{ .Release.Service }}
{{- end -}}Foundation of the Spark on Kubernetes ecosystem, provides Deployment, Service and Configmaps for unified Spark installation. Extends from Common chart.
Connects to the source of eventLogs (HDFS/PVC) and shows Spark event logs. Extends from Common chart.
Provide several ArgoWorflow definitions which are easy to combine into a DAG. This is easy to override and provide your own workflow via in values.yaml of the chart. Extends from Spark Client chart and potentially other infrastructure charts, which will allow to run various workflows.
Combines EventSources and Gateway templates in a single standardized chart.
In our experience we’ve made it to work with HDFS and PVC. But any data source is possible, because the configuration of Spark packages and configuration is very flexible in this setup.
We implemented this type of architecture at one of our clients. Of course, actual implementation is much more complex and filled with lots of organization-specific details. When implementing this architecture it’s important to keep in mind that not all complexity comes from technical challenges.
From the technical side, you need to keep in mind that lots of tools that we used in this proposed architecture are under quite active development. It means that lots of bugs and feature requests are going to be implemented, but on the other side it’s hard to have a stable version of the system with so many components. Another point of consideration is resource allocation. Although Kubernetes can form a core of your computation system, it’s not implemented specifically for the Big Data challenges. There are projects that introduce a more “big data” oriented approach to managing resources with Kubernetes.
Your platform should be easy to maintain, develop and extend to support new use cases. Although we used Helm to hide the complexity of Kubernetes declarations, Helm charts themselves are still quite complex. Also a lot of extra configurations/permissions are needed to maintain all components in sync.
Another important question is user adoption. To fully operate this platform you need to have at least basic knowledge of Kubernetes, Helm, Docker and networking. If you want to avoid it you’ll probably try to bring another layer of abstraction to this platform by creating a UI, which calls Kubernetes API underneath.
Regardless of all the challenges you might encounter, proposed architecture brings a lot of benefits, especially when you want a cloud native data platform with all pros of Kubernetes underneath.


