Data Governance | Topics
Stop Blaming Your Data 
godatadriven 21 Dec, 2020





Updated 22-08-2019: Updated the blog to use the latest version of Apache Druid and Superset
In today’s world you want to learn from your customers as quickly as possible. This blog gives an introduction to setting up streaming analytics using open source technologies. We’ll use Divolte and Apache {Kafka, Superset, Druid} to set up a system that allows you to get a deeper understanding of the behaviour of your customers.
Having your analytics in a streaming fashion enable you to continuously analyze your customer’s behaviour and act on it. For example:
This stack can be an alternative for e.g. Google Analytics and allows you to have all the data directly available within your own environment and keep your data outside third-party vendors. Events are captured by Divolte, queue’d using Kafka, stored in Druid, and are visualized using Superset.
Before going in depth, I would like to elaborate on the used components. Then, an explanation will follow about how to set it up and play around with the tools.
Divolte Collector is a scalable and performant application for collecting clickstream data and publishing it to a sink, such as Kafka, HDFS or S3. Divolte has been developed by GoDataDriven and made available to the public under the Apache 2.0 open source license.
Divolte can be used as the foundation to build anything from basic web analytics dashboarding to real-time recommender engines or banner optimization systems. By using a JavaScript tag in the browser of the customers, it gathers data about their behaviour on the website or application. You’re in full control what you do, and don’t want to capture.
Apache™ Kafka is a fast, scalable, durable, and fault-tolerant publish-subscribe messaging system. Kafka is well known for its high throughput, reliability and replication. Kafka works well in combination with Apache Flink and Apache Spark for real-time analysis and rendering of streaming data.
In this setup Kafka is used to collect and buffer the events, that are then ingested by Druid. We need Kafka to persist the data and act as a buffer when there are bursts of events, that happen when there is, for example, an airing of a TV commercial.
Apache™ Druid is an open-source analytics data store designed for business intelligence (OLAP) queries on event data. Druid provides low latency real-time data ingestion from Kafka, flexible data exploration, and fast data aggregation.
Druid will do the processing of the data and shape it in the form that we request. Existing Druid deployments have scaled to trillions of events and petabytes of data, so we won’t have to worry about scale. It was initially developed by Metamarkets, but got bought by Snap, the parent company of Snapchat. The database was already open source, but got even more open source’ier when moving the software to the Apache Software Foundation.
Druid does not see itself as a data lake, but a data river instead. As the data is being generated by the users, or sensor, or whatever, it flows in the application landscape. Where it is processed and it flows into your database where it is directly available for querying. As with Hive/Presto setups you often do hourly or daily batch, but with Druid the data is available for querying as it hits the database. For me this ties in with the concept of eventually consistent, for the case of druid, this is a matter of milliseconds, with the historical setup with nightly ETL, this might take up to a day. This might give you some serious business value if you’re in a market where you have to act quickly.
Also, not only on ingestion speed of Data is impressive with Druid, also recent benchmarks show a 90%-98% speed improvement over Apache Hive.
Apache™ Superset is a data exploration and visualization web application and provides an intuitive interface to explore and visualize datasets, and create interactive dashboards. Initially developed by Airbnb, but now in the running to become an Apache™ project.
What is more fun than to get an proof of concept running on your own machine? Using Docker it is easy to set up a local instance of the stack so we can give it a try and explore the possibilities.
To set up the system, we start by cloning the git repository:
git clone https://github.com/Fokko/divolte-kafka-druid-superset.git cd divolte-kafka-druid-superset git submodule update --init --recursive
We need to initialize and update the git submodule because we rely on the Kafka container by my dear colleague Kris Geusebroek. These are excellent images and why bother developing ourselves while it is maintained by the crowd? The other images, such as Divolte, Druid and Superset we just pull from the public Docker registry.
Next, we need to build the images locally, and then we start them. Personally I like to explicitly remove the old stances of the images, to be sure there is no old state:
docker-compose rm -f && docker-compose build && docker-compose up
Since we are building the images from scratch, this might take a while. After executing the docker-compose up command, the services are booting. It might take some time before everything is up and running.
After a few seconds we can fire up a browser and check the services:
| Service | URL |
|---|---|
| Divolte | http://localhost:8290/ |
| Druid Unified Console | http://localhost:8888/ |
| Druid Legacy Console | http://localhost:8081/ |
| Superset | http://localhost:8088/ |
| Sample application | http://localhost:8090/ |
Next we need to tell Druid to listen on the correct Kafka topic. This is done by posting a supervisor specification file in JSON format to the indexing service using curl:
curl -X POST -H 'Content-Type: application/json' -d @supervisor-spec.json http://localhost:8081/druid/indexer/v1/supervisor
{"id":"divolte-clickstream"}
If you don’t have curl installed, you can also create the streaming job using the new UI. This can be done under Load data -> Other (Streaming) and paste the content of the supervisor-spec.json in the UI. This supervisor-spec.json file contains the location of the Kafka cluster, the specification of the data and how the data should be indexed. After successfully creating the job, we can see the task in the UI:
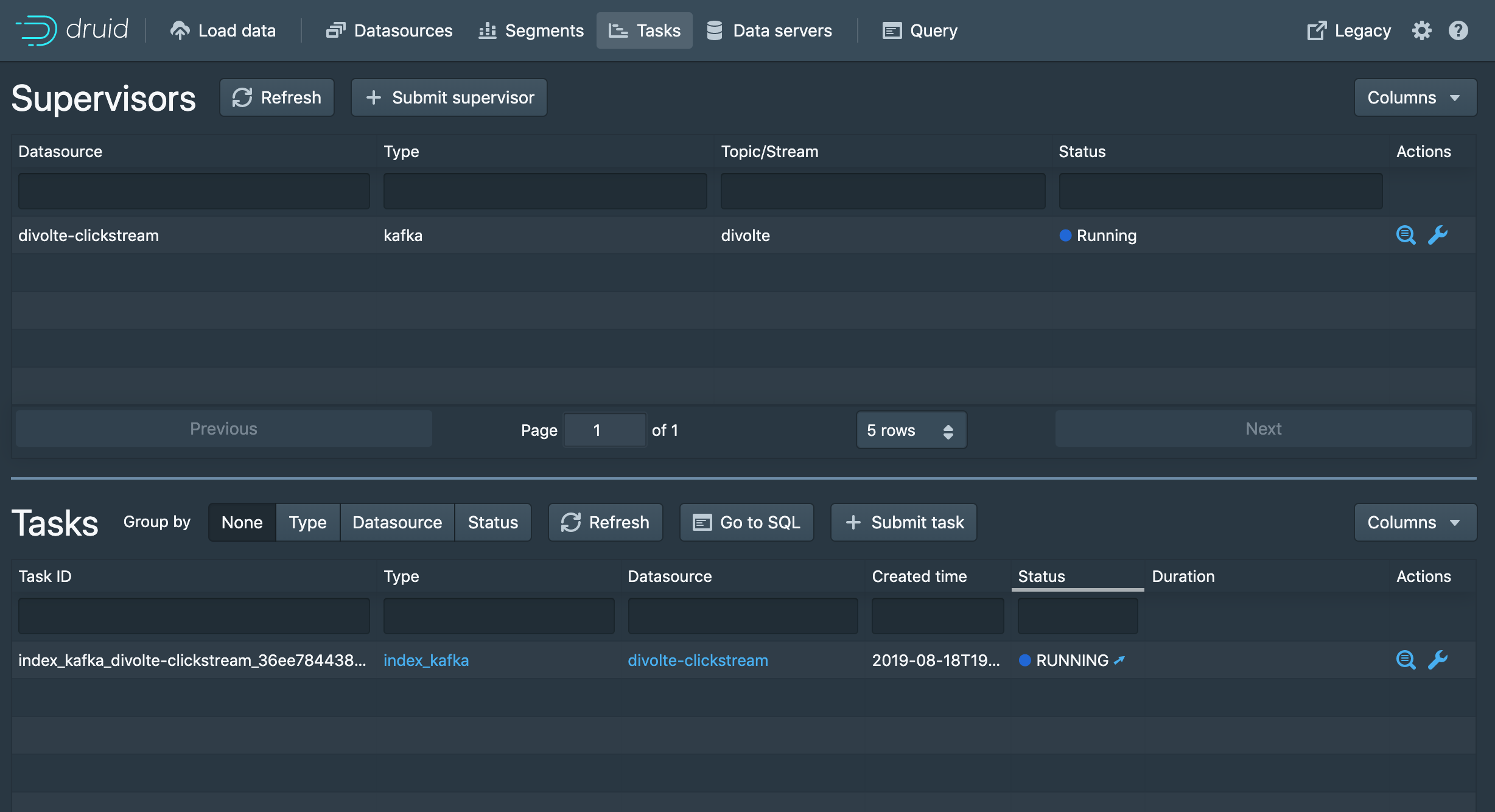
As you might notice, the Druid Restful API is very scriptable, and integrates nicely with orchestration tooling like Apache Airflow. In case you want to de a specific recreation of the table if the schema changes, or if you want to do batch ingestion.
We use a slightly modified version of the default Divolte Avro schema. Divolte can be completely customized according to the needs. For this demo, we’ve added one additional field called technology that we use to demonstrate our sample application. For the schema there needs to be a mapping function, written in Groovy, that is used to populate the fields based on the input. When looking at our mapping.groovy all fields are filled from the metadata, except the technology which is supplied explicitly using an EventParameter.
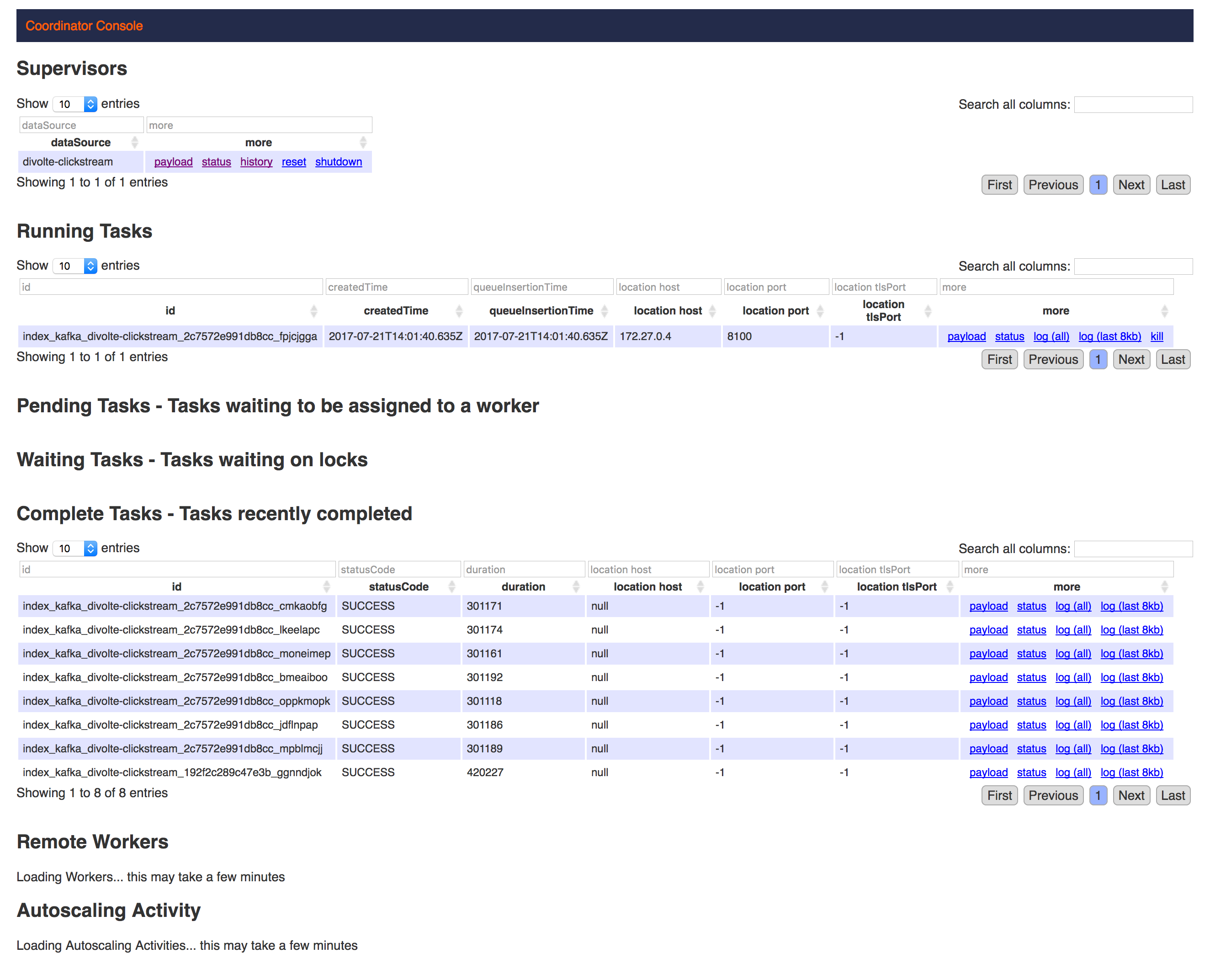
On the indexing console we can see that roughly each five minutes a job is being kicked off. All the new events that come in through Kafka are directly indexed in memory and kept on the heap. After a given timespan the events are persisted on the deep storage, for example HDFS or S3. Before storing the data, it is chunked in segments, by default 500mb, and the bitmap indexes are computed and stored adjacent to the data.
It’s configurable when images are persisted to the deep storage and this should picked based on the situation. The higher the throughput, the shorter the timespan. You don’t want to keep too much events in memory, but also you don’t want to persist too often as small files impose an overhead on the file system.
Let’s take a look at our sample application which is capable of firing events to Divolte. Divolte does not only support web apps but also desktop, mobile or even embedded apps – as long you are able to fire a HTTP request to Divolte.
Visit the app and click on all the technologies you like. Clicking generates events that we will visualize later on.

When clicking on one of the logo’s of the technologies, in the background the action is passed to Divolte using Javascript:
// The first argument is the event type; the second argument is a JavaScript object // containing arbitrary event parameters, which may be omitted divolte.signal('myCustomEvent', { param: 'foo', otherParam: 'bar' })
For more information about how to configure Divolte, please refer to the excellent Divolte guide for more information.
Now that we have configured Divolte, Kafka and Druid, and emitted some events, it is time to configure Superset. Please go to http://localhost:8088/druidclustermodelview/add, as below we can fill all fields with druid as this is the alias in the supplied docker-compose:
Next we have to explicitly refresh the Druid data source by opening a specific url http://localhost:8088/druid/refresh_datasources/, which can also be found in the menu of Superset. This will contact the Druid coordinator and will ask for the available datasources and their corresponding schemas.
First we have to create a new user:
$ docker-compose exec superset superset-init Username [admin]: Fokko User first name [admin]: Fokko User last name [user]: Driesprong Email [admin@fab.org]: fokko.driesprong@xebia.com Password: Repeat for confirmation:
Now everything is loaded, we can start making our first slice. A slice in Superset is a chart or table which can be used in one or more dashboards.
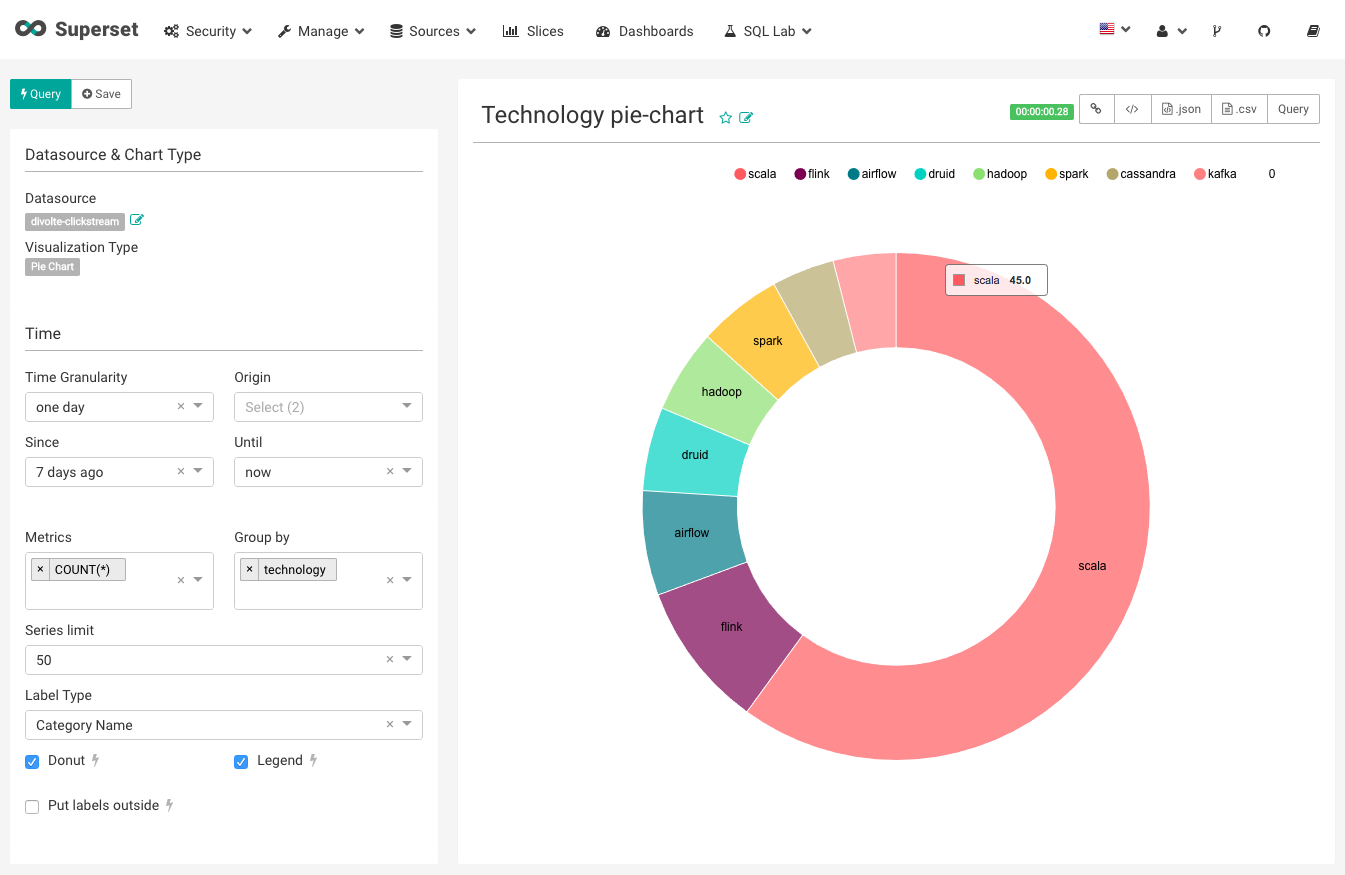
After creating a simple donut-chart as above you can easily visualize the data collected by Divolte in Superset. For me shows that Druid is by far the most popular technology! Click some more on the logo’s to see your dashboard instantaneously change.
This is of course a very simple example, but using Druid it is easy to graph the activity of each technology over time. Also rather complex processing mining activities are easy to visualise using Superset when you implement Divolte event properly.
This example shows the stack of Divolte, Kafka, Druid and Superset. If you want to move this to production, this set of Docker images won’t help you: you will need to set up a proper Kafka and Druid cluster. Superset does not require a lot of resources since all the heavy grouping and filtering of the data is done by Druid. Divolte is known to handle a lot of requests using just a single instance, but it is also possible to put this behind a reversed proxy like Nginx or HAproxy.
In the process of writing this blog I’ve ended up submitting a couple of pull requests, i.e. 3174, 3252 and 3266. This shows the beauty of open source software; when you run into problems, you go down the rabbit hole, find the bug, introduce a fix and make the world more beautiful.
Also, together with one of our clients we’ve developed Scala client for Apache Druid, which has been open sourced to the public. the ING bank needed a convenient way to compose Queries and this is how the Scruid project = (Scala + Druid) has born.
Develop Your Data Science Capabilities. **Online**, instructor-led on 23 or 26 March 2020, 09:00 – 17:00 CET.
Join our A/B Testing and Experiments course where you will learn everything you need to set-up and run perfect A/B tests.


