
Data | Domains
Silver Sponsorship Data Driven Commerce 
Walter van der Scheer 27 Jan, 2016





We can all agree that data is taking a predominant role in the way we do business today. Everybody is trying to jump on the data-driven wagon. The reason for this general agreement being data is an immensely valuable asset that can drive the best possible decision making for any company. Well, any company that makes that data available for their employees. Hopefully all their employees, not just the small data team that is eager to grow but doesn’t have enough resources available. And this is what this blog post is about, data availability. Well, data availability does not sound all that good, so let’s use the preferred word in the data management domain: data democratization.
What is data democratization then? I think most of you have heard of this term by now, so I won’t bother you too much with detailed explanations. In a nutshell, data democratization is about making sure that every team in the company has access to data. What data, you may ask. Well, obviously we don’t want to overwhelm every team with every detailed piece of data, but at least let’s make sure that the finance team has access to all transaction and invoice related data and that the marketing team can check the status of their latest marketing campaigns. This is, of course, just an example. I’m sure that while reading this you can come up with around a thousand more.
Now we have the vision. Everybody has timely reports in the company, decisions are being made left and right based on the most solid evidence, we leave every Friday at two o clock to drink caipirinhas because the business is going as smooth as it gets. Driven by the promise of this utopia, we try to steer our efforts into making it happen but somehow things don’t work out as smoothly. Why? Because making data available for everybody is not as easy as it sounds, and traditionally, it used (remember this past tense) to take a lot of time from a very crucial resource in the data world, the data engineer.

Data engineers, those rare diamonds that are so hard to find and yet are so needed. As great as they are, they are the reason why data democratization is not wide spreading as fast in most companies. I mean, this is not their fault perse, all of the ones that I’ve met are really nice people and mean no harm. This is more of a supply and demand problem. There are a lot of departments that need accurate and timely data in a company, but there’s not enough data engineers to serve them. You may be thinking: “What a nonsense! So we hire more!”. Well, that won’t be as easy as it sounds. Despite all the hype around data scientists, most tech job reports agree that data engineer is the most demanded role (e.g. Dice 2020 Tech Job Report). Demand heavily outgrows supply.
Why did we use to need data engineers in the first place? You may already know the answer to this question, but still, I want to cover all the bases. We need them to build the data platform from which your teams, departments, units, can self-service from. How hard is it to build this data platform then? Well, it is hard. But the hardest part is not selecting the technology stack to use, or the cloud to deploy. The hardest part is building all the required data pipelines so that your teams can have access to all their needed data sources in one centralized place. Then, maintaining those pipelines can also be a painful job that takes an immense amount of time out of your data engineering team. Many of these pipelines are relatively simple Extract & Load jobs, or, in other words, copying data from a data source and replicate it to your data lake or warehouse of choice. They are not exciting to tackle and yet quite hard to maintain.
Concluding, we need data engineers and, most importantly, we need to attract them, but there are not many, and they don’t like doing unexciting, repetitive work that is horrible to maintain. This points into one direction. Democratizing data shouldn’t be about hiring a hundred new Data Engineers (maybe five will do). Democratizing data should be about reducing engineering work.

How do I reduce the engineering work? You may ask. Well, I kind of spoiled it with this section’s title. Indeed, you need to enable your analysts. What does enabling imply? Well, enabling means that your analysts should start changing their “data role” from data consumers to data owners.
At this point you maybe be thinking that I’m contradicting myself. I’ve just mentioned how building a data platform is a complex job reserved for a certain amount of people that are hard to find (i.e. data engineers). However, I also did mention that a big part of this job implies building and maintaining data pipelines from the required sources to the point of consumption. Imagine if all these data pipelines, these data transformations, the data modeling, could be easily done and maintained by your analysts with little to no support from your data engineering team. Your teams could have unlimited access to data resources and could easily consume data on-demand without having to make request after request to the data team. Your data engineers will happily focus on tougher assignments, for example building streaming systems for real-time decision making or placing machine learning models into production. Everybody is happy. It seems as if I’m drifting to utopialand again… or maybe not.
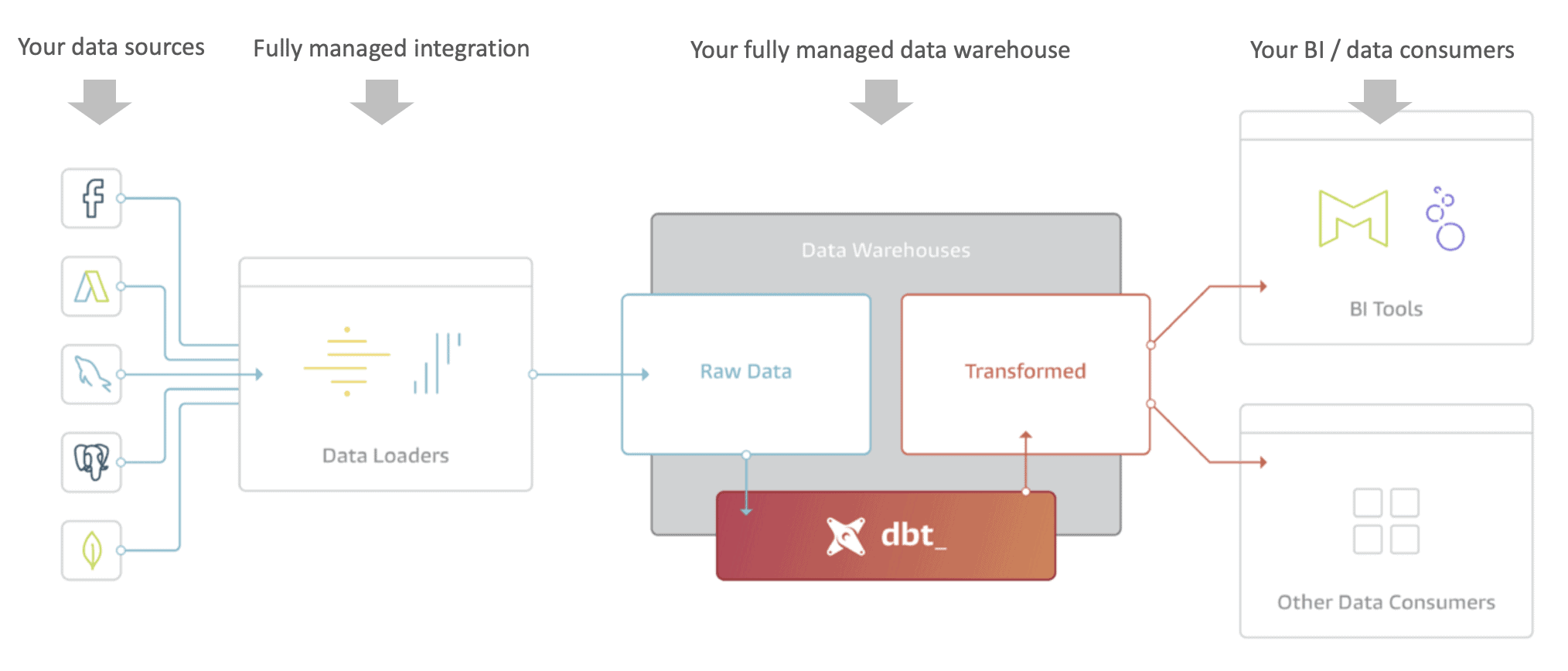
Source: blog.getdbt.com
Data democratization is closer than ever, and the Modern Data Stack. What is the Modern Data Stack? It’s a set of tools that reduce the complexity of setting up and tuning a data platform. It heavily reduces all the unnecessary work of moving all your sparse data sources to one place by automating this tedious Extract & Load jobs. With tools like Fivetran or Stitch that have pre-built connectors to hundreds of data sources, moving the data to your data warehouse has never been easier. The best part about using these tools is that they have a super intuitive UI that all your analyst can use without even worrying about writing a line of code.
Now your data is in the warehouse and, of course, you need to perform some analytics. This means activities such as modelling data, aggregating data or joining different sources to enrich the value of your data. That seems like engineering work, right? Thankfully, not that much anymore. That’s the incredible thing about having your data in the data warehouse, you can write all your transformations in SQL! Being declarative, SQL is the most intuitive language for data transformations. SQL is not only intuitive, most analysts these days have a good knowledge of it. Another nice advantage is that modern data warehouses (BigQuery or Snowflake) auto-scale when they have super heavy workloads, so you can forget about Spark even for your heavy transformations! Complexity is reducing by the second.
If you are a tech fan, you may be thinking now how is it possible to manage all these transformations when they scale up to the hundreds. Saving hundreds of SQL queries in some folder is not really an easy thing to maintain, right? What about if I want to update one of those transformations? Or roll back to a previous version of one of my SQL scripts? If you are already at this stage, then dbt (Data Build Tool) will be your best friend. dbt will help you manage all of this complexity just by integrating some nice practices like documentation, transformation/model lineage (i.e. which transformation goes first), data testing (i.e. weird to have transactions with negative values) and some nice version control with Git to make sure that you have everything in one place and you can track versioning.
All these technologies together definitely sound like the right combination, but still we need to empower our analysts to get closer to these concepts. This road will probably take them to embrance a new role, the Analytics Engineer. If some of your analysts put on the Analytics Engineer hat, you will probably be moving closer to democratizing data at your company. Explaining what an Analytics Engineer is can take at least another bog post, like, for example, this one. For now, you may think of this role as one of your data analysts learning how to use some of the tooling and practices that I’ve describe above.
If you got to this point, it means that this discourse resonates with what you feel you need at your company. This is, in some good engineer style bullet points:
Data democratization is 30% about the technology stack and 70% about the attitude. The good thing is that the 30% just got way better. Moving data to the consumption points has never been this easy, fast and scalable. If you want to get deeper into the details or simply just discuss some of the points of this post, please feel free to reach out.
We have a really active community at GDD around the Modern Data Stack and Analytics Engineering. For upcoming events, please check our linkedin event page and our Analytics Engineering meetup group.